モノリシックなプロジェクトにおいて、トップレベルのディレクトリ構成が異なる 2 つのディレクトリ構成を考え、それらの違いは何で、どちらが優れているか?という問いについて考えた。そして、「複雑な概念をトップレベルのディレクトリ構成にした方が良いのでは?」という結論に落ち着いた話をする。
はじまり
ちょっとしたシナリオを想像してみよう。
プロジェクト立ち上げ期
「最近のトレンドはレイヤードアーキテクチャだ!」
そう言って、プロジェクトはスタートした。
.
├── application
│ ├── xxx_usecase.go
│ ├── xxx_repository.go
│ ├── yyy_usecase.go
│ └── yyy_repository.go
├── domain
│ ├── xxx.go
│ └── yyy.go
├── infrastructure
│ └── xxx_repository_impl.go
└── presentation
│ ├── xxx_handler.go
│ └── yyy_handler.go
ドメインの成長期
プロジェクト立ち上げ期に作ったアーキテクチャは、依存関係を把握するのに役に立っていた。 ビジネスが成長するにつれて、ドメインはどんどん複雑になっていくが、どのディレクトリにコードを置けば良いのか迷う必要がない。
よく出来たディレクトリ構成だと思っていたが、新しくプロジェクトに参加した人からこんなコメントをもらった。
「機能間の繋がりがいまいち分からない。」
各レイヤーのディレクトリの下にサブディレクトリを切っていなかったため、レイヤーに関係する全てのファイルが 1 つのディレクトリ置かれていた。 相互に呼び出されることない全く異なるドメインのファイルが同じディレクトリに置かれており、認知負荷が高まっていた。
.
├── application
│ ├── xxx_usecase.go
│ ├── xxx_repository.go
│ ├── yyy_usecase.go
│ ├── yyy_repository.go
│ └── # ここに数十、数百のファイルが置かれていた
├── domain
│ ├── xxx.go
│ ├── xxx_foo.go
│ ├── xxx_bar.go
│ ├── yyy.go
│ ├── yyy_hoge.go
│ ├── yyy_fuga.go
│ └── # ここに数十、数百のファイルが置かれていた
├── infrastructure
│ ├── xxx_repository_impl.go
│ └── # ここに数十、数百のファイルが置かれていた
└── presentation
│ ├── xxx_handler.go
│ └── yyy_handler.go
│ └── # ここに数十、数百のファイルが置かれていた
ずっとプロダクトに携わっている人間にとっては、ほぼ全ての機能を把握しているので、特に困らない。 しかし、新しいメンバーにとっては必ずしもそうではない。
このような状況の対処するために、DDD の文脈での「境界づけられたコンテキスト」ごとに、サブディレクトリを切ることにした。
.
├── application
│ ├── xxx
│ │ ├── usecase.go
│ │ ├── repository.go
│ │ └── # そこまで多くないファイル数
│ └── yyy
│ ├── usecase.go
│ ├── repository.go
│ └── # そこまで多くないファイル数
├── domain
│ ├── xxx
│ │ ├── foo.go
│ │ ├── bar.go
│ │ └── # そこまで多くないファイル数
│ └── yyy
│ ├── hoge.go
│ ├── fuga.go
│ └── # そこまで多くないファイル数
├── infrastructure # 省略
└── presentation #省略
これにより、
- レイヤードアーキテクチャ
- 複雑なドメインの理解容易性の向上
の両方を達成できるようになった。 めでたしめでたし。
マイクロサービスにする場合のディレクトリ構成
前の例では、ビジネスが成長してもモノリシックなプロジェクトのままであることを仮定していた。 では、マイクロサービスで分割する場合どうなるだろうか?
この場合、ルートのディレクトリ構成は境界づけられたコンテキストごとに分離した構成となる。
.
├── xxx # ここが1つのマイクロサービスになる
│ ├── application
│ │ └── # そこまで多くないファイル数
│ ├── domain
│ │ └── # そこまで多くないファイル数
│ ├── infrastructure
│ │ └── # そこまで多くないファイル数
│ └── presentation
│ └── # そこまで多くないファイル数
└── yyy # ここが1つのマイクロサービスになる
├── application
│ └── # そこまで多くないファイル数
├── domain
│ └── # そこまで多くないファイル数
├── infrastructure
│ └── # そこまで多くないファイル数
└── presentation
└── # そこまで多くないファイル数
あれ、トップレベルのディレクトリ構成が違うぞ?
ここで少し疑問が生じる。 上の話の中で、ドメインが複雑になったときのディレクトリ構成として、 2 つのパターンを紹介した。
- トップレベルがレイヤーのディレクトリ構成
- トップレベルが境界づけられたコンテキストのディレクトリ構成
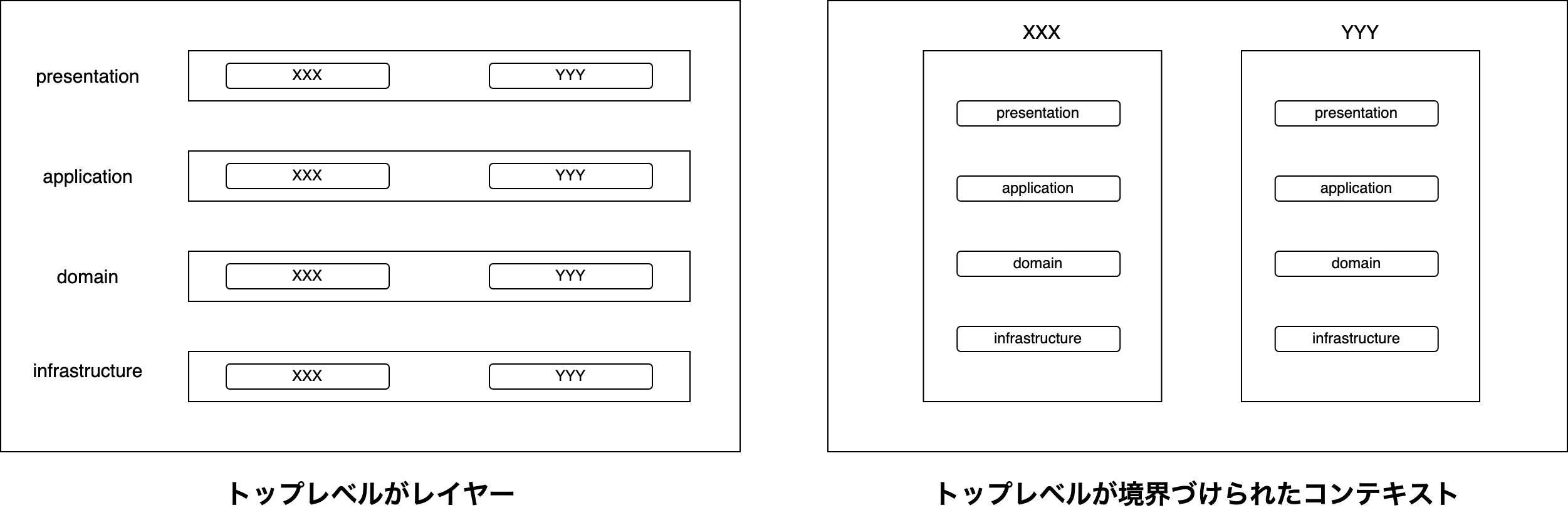 ディレクトリ構成のイメージ図
ディレクトリ構成のイメージ図
話の流れ的には後者の構成はマイクロサービスを仮定していたが、どちらの構成もモノリシックなプロジェクトに適用可能だ。
また、どちらの場合も
- レイヤードアーキテクチャ
- 複雑なドメインの理解容易性の向上
は達成できる。
では、モノリシックな場合において、この 2 つのディレクトリ構成の違いはなんだろうか?どちらが優れているのだろうか?
ディレクトリ構成は人間のためのもの
手始めに、ディレクトリ構成が「何のため」にあるのかを考えてみる。
前提として、ディレクトリ構成は、必ずしも技術的な制約によって強制されているものではない。 レイヤーで区切ったディレクトリ構成を規約としているフレームワークは例外だが、この記事のような議論をするプロジェクトでは、特に制約のない言語・フレームワークを使っている場合が多いだろう。
では、何のためにディレクトリを切っているか?
この問いに対する答えは 「人間のため」 に集約されると考えている。
レイヤーで区切ったディレクトリ構成は、人間が依存関係の把握をしやすい状態を目指している。 境界づけられたコンテキストによる分割では、人間がドメインを適切に理解できる状態を目指している。 どちらも人間のためだ。
結局のところ、ディレクトリ構成は人間、つまりそのプロジェクトに携わる(現在・将来に関わらない)開発メンバーにとって「良い」ものであれば何でもよいのである。
「良い」ディレクトリ構成は、ファイルの発見容易性とプロジェクトの理解容易性が高い構成である
「良い」ディレクトリ構成の、「良い」とは何なのか?
私は 「ファイルの発見容易性とプロジェクトの理解容易性が高い状態」 が「良い」ディレクトリ構成なのではないかと考えている。
具体例として、「ユーザ情報を DB に保存する処理が知りたい(ただし、その処理がどのファイルにかかれているを知らない)」といったユースケースを考えてみよう。
このとき、先程例に挙げたようなディレクトリ構成を採用している場合は、「user ドメインの infrastructure を探してみよう」となることが多いだろう。 この探し方では、ディレクトリ構成はファイルに対するインデックスとして機能している。 このユースケースでは、ディレクトリ構成はファイルの発見容易性を高めるために使われていることが分かる。
別の例として、「あるディレクトリやファイルがどのような処理をしているのか知りたい」といったユースケースを考えてみよう。
この場合は先程の例と逆で、「user ドメインの infrastructure パッケージだから、ユーザに関する技術的な詳細の実装をしているのだろう」とディレクトリ構成から実装内容を推測できるため、プロジェクトの理解が捗る。
トップレベルのディレクトリと複雑さ
話を戻そう。
我々は、
- トップレベルがレイヤーのディレクトリ構成
- トップレベルが境界づけられたコンテキストのディレクトリ構成
の違いは何で、どちらが優れているのか?という問いについて考えていた。
先程の「良い」ディレクトリ構成に関する議論を考慮すると、この 2 つの構成の違いは 「ファイルの発見容易性が違う」 と考えられるのではないだろうか?
ファイルを探すときに、先にレイヤーで絞り込むか、ドメインで絞り込むかによって、「ファイルの発見容易性」が変わるのではないか? 「ファイルの発見容易性」が違うことがそのままディレクトリ構成の優劣につながるのではないか?
この仮説について考えてみよう。
ディレクトリ構成は RDB の複合インデックスとみなせるのではないか?
この仮説を考えるために、似た概念を比較してみる。 例えば、RDB の複合インデックスはファイルをディレクトリ名から探し当てる動作と似ているのではないだろうか。
- RDB のインデックスもディレクトリ構成も木構造で表現できる
- どちらも検索のためのデータ構造
の 2 点を考えると、この考えは自然な気がする。
このような考え方をすると、元々の問いは「どちらの複合インデックスがより優れているのか?」という問いに変換できそうだ。
- 複合インデックス (
layer_name,bounded_context_name) - 複合インデックス (
bounded_context_name,layer_name)
複合インデックスはカーディナリティの高いものを先に設定する
では、この 2 つの複合インデックスはどちらの方が良いか?
一般的なプラクティスでは、カーディナリティ が高いものから順に貼っていくことが推奨されている。 最初のインデックスキーでより多く絞り込める方がパフォーマンスが高いからだ。
つまり、
- トップレベルがレイヤーのディレクトリ構成
- トップレベルが境界づけられたコンテキストのディレクトリ構成
においては、カーディナリティが高い、すなわちより複雑な方をトップレベルのディレクトリ構成にした方が優れた発見容易性を達成できるのではないだろうか?
レイヤーとドメインの複雑性は時間の経過によって変わる
レイヤーとドメインの複雑度はビジネスのフェーズによって変わる点に注意した方が良さそうだ。
まず、レイヤーに関しては、ビジネスが成長してもレイヤーの数はさほど増えない。 一方で、ドメインはビジネスが成長するに連れてどんどん複雑になっていく。
つまり、レイヤーの方が複雑なビジネスの初期は、レイヤーをトップレベルのディレクトリ構成にした方が良い。ビジネスが成長するにつれてドメインの方が複雑になった場合は、境界づけられたコンテキストをトップレベルのディレクトリ構成にした方が良くなるのではないか。
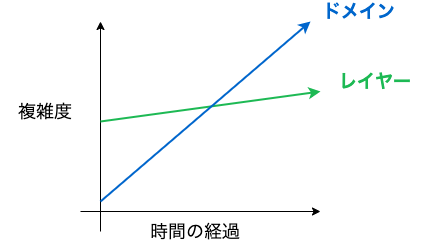 時間の経過に伴う複雑度の変化
時間の経過に伴う複雑度の変化
これは、昨今のマイクロサービスの流れとも一致する考えだ。
まとめ
モノリシックな場合において、この 2 つのディレクトリ構成の違いは何で、どちらが優れているか?という問いを立てた。
- トップレベルがレイヤーのディレクトリ構成
- トップレベルが境界づけられたコンテキストのディレクトリ構成
その過程でディレクトリ構成は誰のためのもので、どういう点で優れていないのかいけないかについて考察した。
その考察を元に、問いの判断軸は「ファイルの発見容易性」なのではないかという仮説を立てた。
この仮説とデータベースの複合インデックスの考え方をから、「レイヤーと境界づけられたコンテキストとで、複雑な方をトップレベルのディレクトリ構成にした方が良いのでは?」 という考えに落ち着いた。 ただし、どちらがより複雑なのかは時間の経過によって変わることに注意しなければならない。
おわりに
実はこの結論に対して私はあまり自信を持てていない。 トップレベルのディレクトリ構成が境界づけられたコンテキストのプロジェクトを運用した経験がなく、机上の空論ではないか?と自分を疑っている節がある。 また、このような構成を採用したという話を日本語のテックブログで読む機会も少なく、業界的に流行っていないような気もする。
理由として、以下のようなことは考えられるが正解は分からない。
- どのドメインにも属さない共通機能の置き場所がない
- トップレベルに共通機能置き場のディレクトリを生やせば解決する気もする
- 歴史的経緯により、循環参照になってしまうので適切に境界づけられたコンテキストで分割できない
- マイクロサービスに分割していて、それぞれのリポジトリでドメインがそれほど複雑にならない
- 現状維持バイアスで、ドメインが複雑になってもガツッとディレクトリ構成を変える勇気がでない
皆さんのプロジェクトではどうしてますか? コメントお待ちしています。
追記
下書きを書き終えた後に知ったが、pospome さんの「pospome のサーバサイドアーキテクチャ(PDF 版)」にて、横割りと縦割り という形で整理されていた。
